写一个 Python 爬虫
写一个 Python 爬虫其实挺容易的,也许过程中需要不停的调试,但爬虫的代码绝对短小精悍!
肇事者爬虫
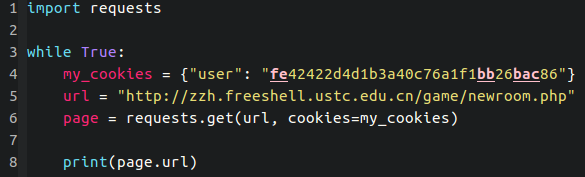
这就是我昨天把郑子涵五子棋网站搞挂的 Python 爬虫,文件名为 spider004.py。没错是我写的第四个爬虫…今天为了防止我继续恶意开房,他给网站加了验证码。目前我还无能为力= =
HTTP 协议
要写一个爬虫,首先你得懂 HTTP 协议的一些东西。我当时是看了这篇文章《HTTP协议详解》。我简单说下自己的理解:
当你用浏览器访问网页的时候,其实是经历了这么一系列的过程:你通过浏览器发出 HTTP 请求 (HTTP Request),发送请求有多种方法,常见的两种是 GET 和 POST。网页的服务器端收到你的请求进行处理后,就会给浏览器响应 (HTTP Response)。而 HTTP Request 和 HTTP Response 都是有参数哒,你可以通过 F12 来看。
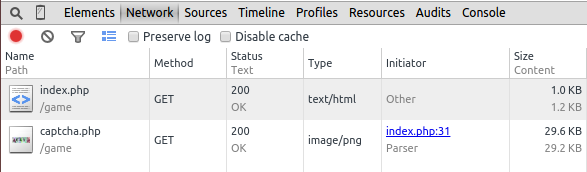
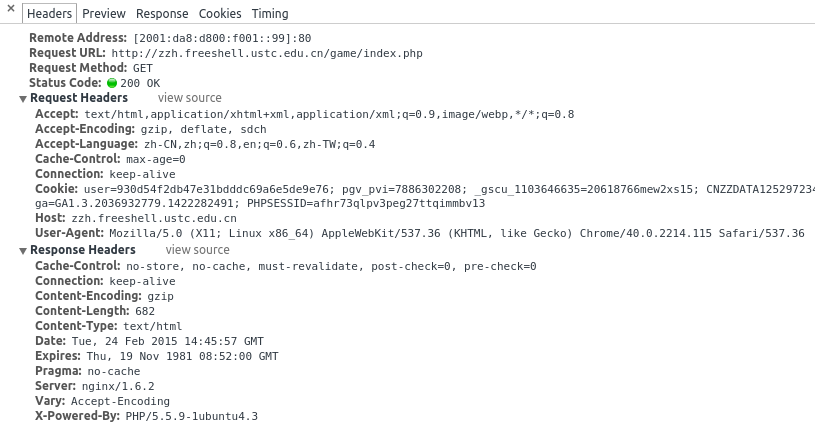
这很好理解,因为交互各种各样,访问不同的网址,是否登录账号,用什么浏览器,甚至在不同的时间发起请求,都会导致 HTTP Request 的不同。而服务器端挂了,状态码(status_code) 可能是 502 Bad Gateway,又或者 404 Not Found,这都是平时常见的错误,就是 HTTP Response 的一部分。(你可能会把它统称为:“ 啊,网页怎么打不开了!”,其实打不开也是有不同的原因的)。
差不多先了解这些,之后写爬虫的过程中,我们还会常用 F12,利用 HTTP Request/Response 的信息来调试。
Python Requests Module
所谓的网页爬虫,就是模仿浏览器向服务器发送特定的请求,并且返回获取的内容。而 Python 为此提供了一个很好用的模块,Requests 模块。
我最早是看了这个教程《HTML Scraping》,并且按照上面操作了一遍。这个教程提到抓取网页内容可以用的两种定位方法 XPath 和 CSSSelect,虽然我都没学会..
然后还看了这两个教程,一个是《Requests: HTTP for Humans》官方文档,另一个是《Using Requests in Python》简单教程。
我们可以简单的演示一下(终端中打开python3):
1 | import requests |
如果你需要的是抓取网站获取的信息(显示的HTML文件),可以把 page.text 部分输出到文件中。
把网站搞垮的具体细节
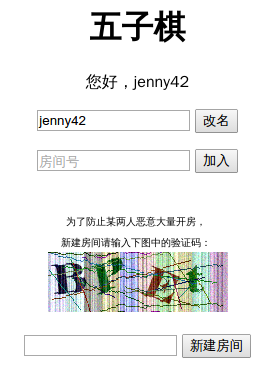
我观察到五子棋网站下棋开的房间是随机6位数,而且保存所有的棋盘信息,也就是你下完棋哪怕两个人都退出了以后,房间还是被占用的,你们还可以之后再进去继续玩。也就是,“如果我把所有的房间都开满了,那其他人没法开新的房间,也没法再已经被我开的房间里下棋了”←我对网站的攻击就是基于这个思路。
首先,自己打开浏览器里的匿名窗口操作一遍(匿名窗口是防止 cookie 混乱),并且按F12打开控制台, 观察到我新建房间时发出的请求获取的文件,如
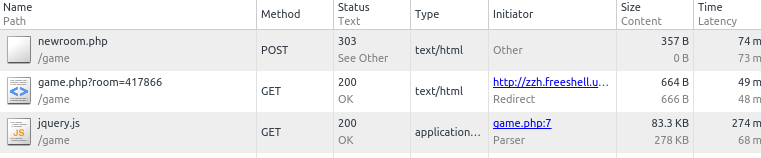
戳进去,拿到 cookie 和 url,然后作为代码的参数
我把它写成了死循环…然后,运行这个代码。每次访问http://zzh.freeshell.ustc.edu.cn/game/newroom.php这个url,它就会返回一个新房间的地址,相当于完成了开房的动作。
以上这小段代码也是我经过一会时间修改才搞定的…
确认可行之后,我开了10个终端…一起刷,结果一个多小时后,网站就挂了。。。整个 freeshell 登不上去了。经神秘管理员重启之后,网页上已经无法新建房间,随机输入一个房间号都有一个叫做 root 的玩家在里面。
后续情节…
肇事者表示刚刚学会写爬虫所以拿了个好朋友的网站来玩…神秘的 freeshell 管理员其实是帮凶,他不仅指导我写脚本,而且在我开始攻击之后,突发奇想想要测试该 freeshell 的抗压能力…搞得该站长一直以为是有人通过 2081号 freeshell 攻击。我做了坏事,看对方没有反应,先是主动上去报了 bug(“哎呀,你的五子棋没法玩了耶”→好贱),最后被查出来以后主动承认并道歉…我表示一开始还挺兴奋,后面觉得这么做还是挺不好的…要是对方生气了呢,是吧?
