编译时发生了什么?
一、你知道编译的时候发生了什么吗?
你知道C语言编译时发生了什么吗?
是不是像我一样嫌弃老师上课讲的冗长又抽象,搞什么嘛!
说那么多还不如把细节展示给我看!
这周的Shorts视频中有一集叫做Compilers,7分钟不仅详细讲了编译时的四个步骤,还打开查看了 -E -S -c之后的文件。看完感到极大的满足,于是动手试了一遍,下面把视频转换成图文,跟我一起学C语言啦!

首先,写一个大家非常熟悉的”hello world!”代码

哦,我用的编辑器是emacs,操作系统是ubuntu(linux),然后直接在终端(Terminal)下用gcc编译,然后 ./a.out 执行。运行正常
这就完成了一次编译到运行的操作。平时我做作业也都是这样,并没有理会从C语言到机器语言的编译过程具体是什么样。
二、编译的四个步骤
gcc的编译流程分为四个步骤,分别为:
- 预处理(Pre-Processing)
- 编译(Compiling)
- 汇编(Assembling)
- 链接(Linking)
(1)编译预处理(Pre-Processing)
先输入这一行命令:gcc -E 目标文件.c

回车后就被刷屏了….

把这些代码导入到一个hello2.c的文件中

打开后
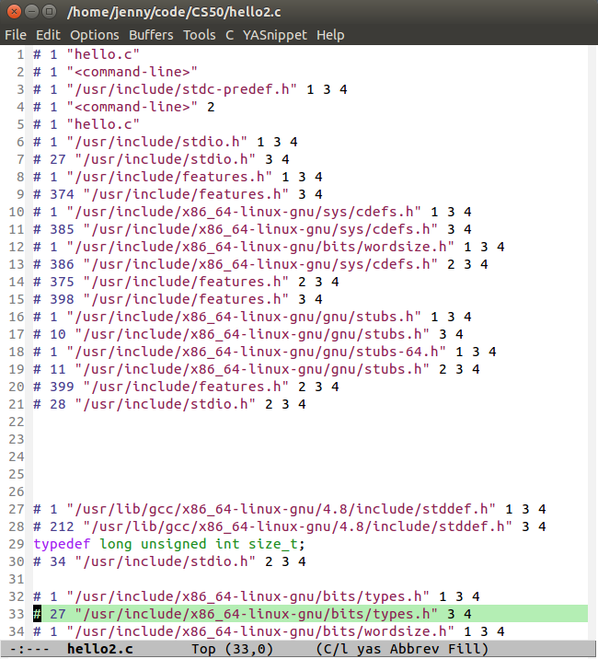
这是什么鬼!长这么奇怪= =
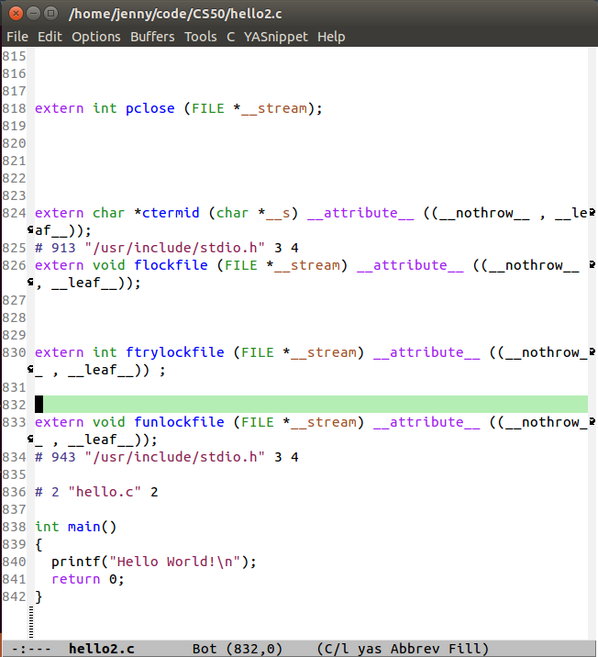
哈,居然有800多行,拉到最后终于看到熟悉的 “hello world!”代码片段惹!
这就是编译预处理啦~ 搜了一下什么是编译预处理
【摘】预编译的主要作用如下:
●将源文件中以”include”格式包含的文件复制到编译的源文件中。
●用实际值替换用“#define”定义的字符串。
●根据“#if”后面的条件决定需要编译的代码。
是嘛~刚刚刷屏那个就是把源代码中 #include <stdio.h> 这一行替换成了834行代码..
再拿宏定义试试,注意第3行

相同操作之后,对比预处理之后的.c文件

喏,836行之前没有区别!只有原来 #define name “Jenny” 那一行消失了,取而代之的是源代码中 printf(“Hello %s\n”,name); 中的name 被换成了 “Jenny”

这就是传说中的,define只做“文本替换”啦
(2)编译(Compiling)
下面用 gcc -S 目标文件.c 来编译,用C语言代码 生成 汇编语言

打开编译后的 hello.s 文件

又是什么鬼,完全看不懂….
(3)汇编(Assembling)
用 gcc -c 目标文件.s 把

打开 hello.o二进制文件

这就是传说中的机器码了,你看到中间的 “hello world!” 了吗? *Bonus 直接修改二进制文件
让我们改改机器码试试!→_→ 
改成 no zuo no die ….
运行试试

玩坏了 ..>_<.. 一定是字节不一样!!

改成hello jenny

这样就行啦!
*Bonus 用十六进制看机器码!
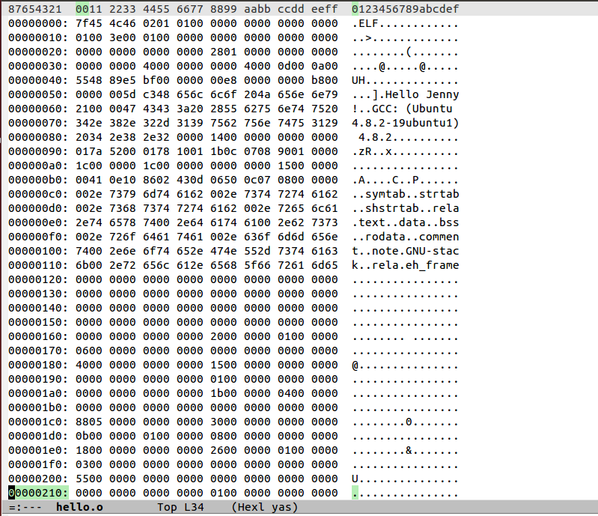
哈哈哈,有点像传说中的10101010串了吧!我不知道怎么通过二进制查看机器码….

再改成nozuonodie!!
这次成功了

(4) 链接(Linking)
刚刚一直到这个步骤,其实代码都不能执行。可执行文件 a.out 是我之前一步gcc hello.c生成的。
最后一步链接,需要在二进制文件 hello.o 的基础上,生成可执行文件 .out

命令为 gcc hello.o 列出当前文件夹下面的文件,可以发现只有 hello.out 是绿色的,并且最左边一堆rwx里面只有hello.out带有x,那些rwx表示的是”read”,”write”,”execute”的权限啦!
